
开场白
来阅读一下《GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism》原论文。
( •̀ ω •́ )y
GPipe
Question:如何在超出单个加速子内存限制的情况下扩大模型容量?
现有的解决方式缺乏泛用性。
GPipe:流水线并行库,以“层”的序列方式进行工作,将不同“层”划分给不同的加速子。同时,GPipe提供了一个自动划分批次(以连续的多个层视为一个单元放到一个加速子上)的算法,在多卡上提供线性增速的效果。
应用测试:
- 图像分类器
- 多语言翻译器
实现
基于Lingvo框架实现。
Lingvo是一个为协作深度学习研究提供完整解决方案的Tensorflow框架,特别关注序列到序列模型。
Lingvo基于组件块构建学习框架,因此方便扩展。
接口描述:
| 模型层数 | 给定分区数 | 第层函数 | 第层权值 | 第层计算开销(用于评估GPipe性能) | 第个分区的层集合 | 微批次数目 |
用户只需给定、、三个参数。
GPipe分区算法
思路:极小化各个分区的开销评估的方差,以极大化流水线效率。
前向传播阶段,将每个大小为的mini-batch划分为个micro-batch,再划分到个加速子。
反向传播阶段,针对每个mini-batch,每个micro-batch基于原有参数独立计算梯度,并在mini-batch的末尾收集并用于更新参数。
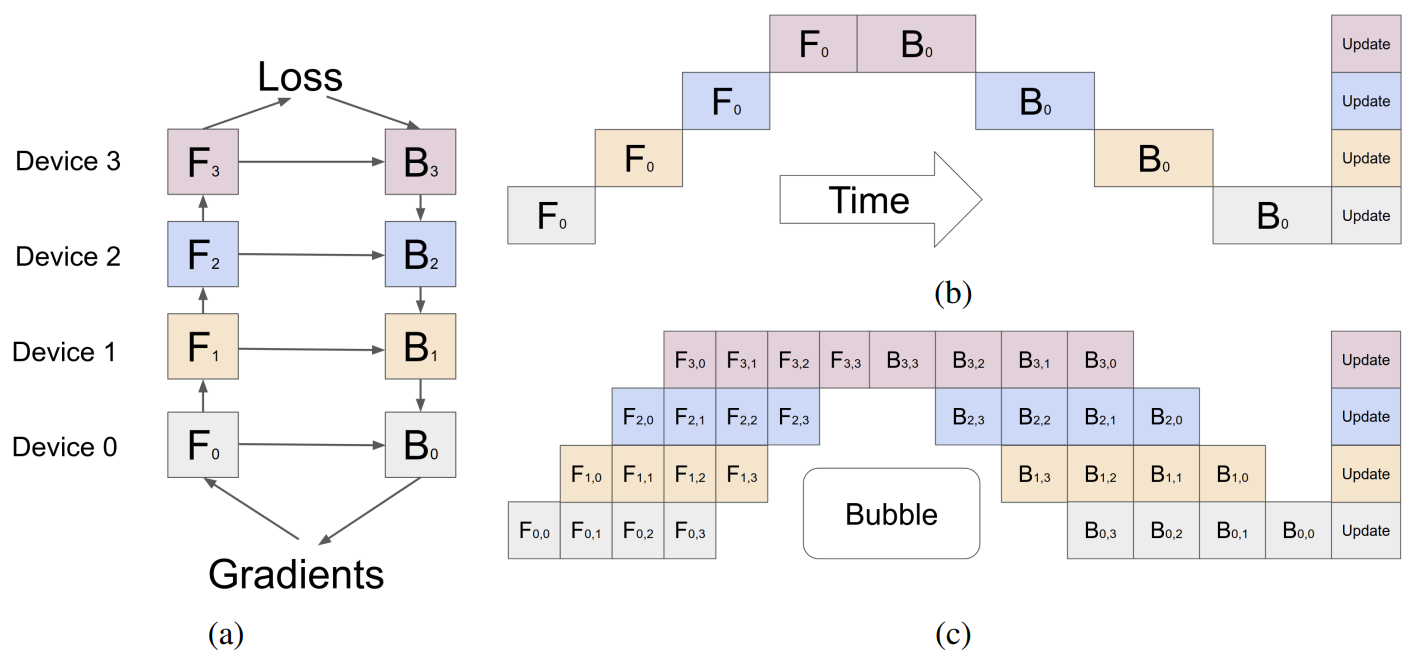
复杂度分析
存储复杂度从 优化到了 ,其中是micro-batch的大小,是每个区内的层数。
时间复杂度优化原文没有计算出来(只提到了Bubble的影响),实际上应该是优化了接近倍的。(引入了通信开销和分区不平衡的开销)
实测性能评估
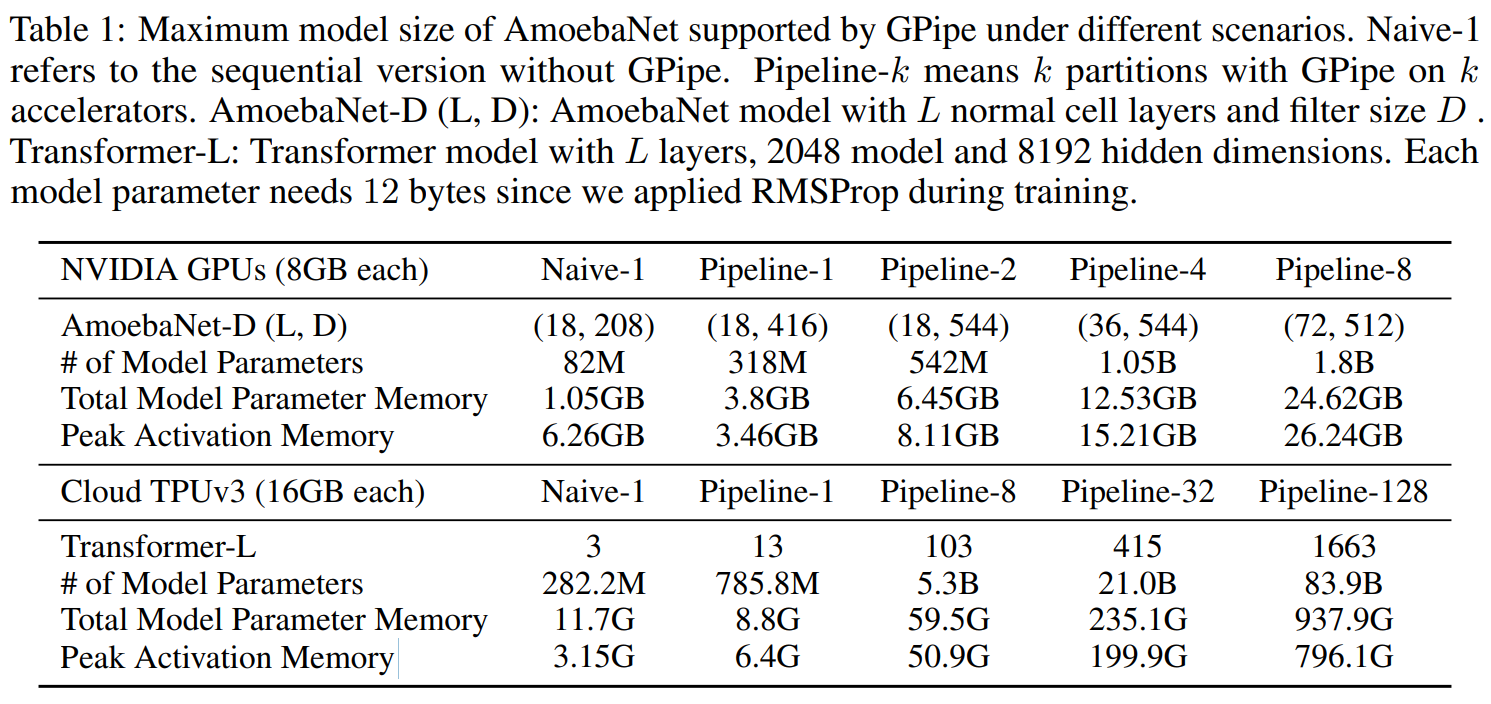
比较Naive-1和Pipeline-1可知模型的最大允许容量提升巨大,比较不同的Pipeline-k可知多卡扩展性很好。
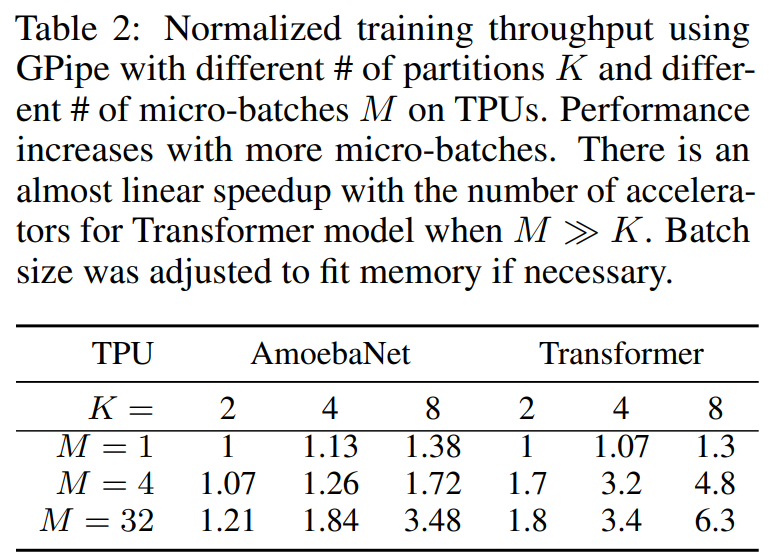
在足够大的情况下,模型训练速度基本随着线性加速。
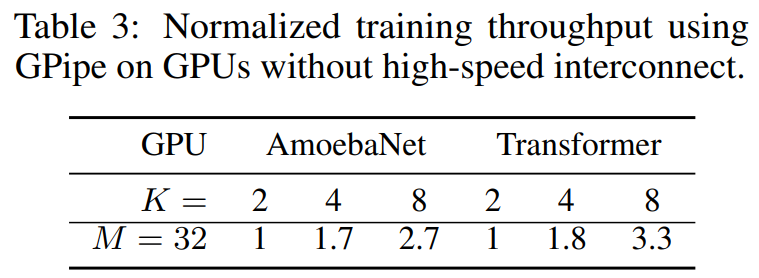
在未使用NVLinks等高速互联设备下,发现表现没有降低太多,说明通信带来的开销并不大。
准确率评估
图像分类器
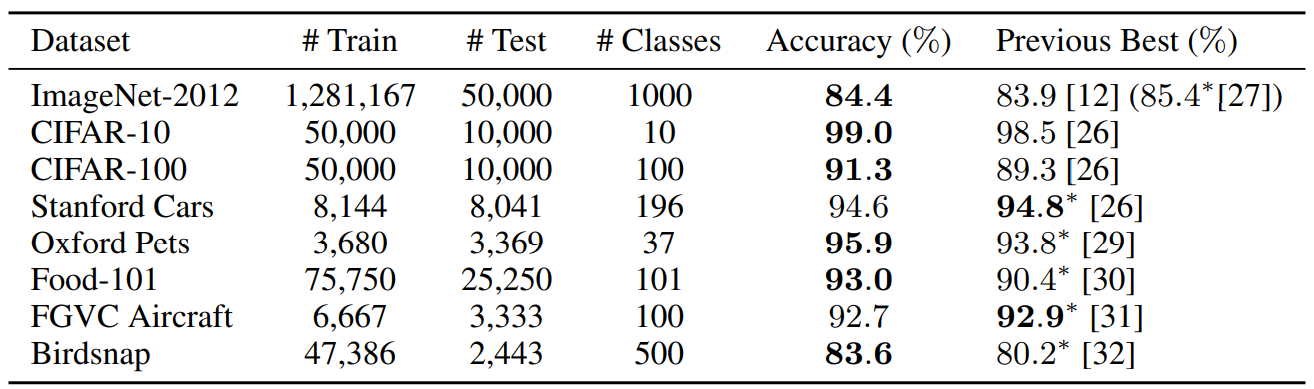
扩大AmoebaNet参数量,效果如图。
在其它数据集上,使用扩大最后一层参数的ImageNet进行微调,得到更优准确率。
多语言翻译器
由于大量的平行语料库可用,神经机器翻译(NMT)已经成为任何用于NLP的架构的基准任务。
基于单个Transformer,分别进行深度和宽度的扩展。
表示有个编码层和个解码层,的前向隐藏维度和个注意力头。
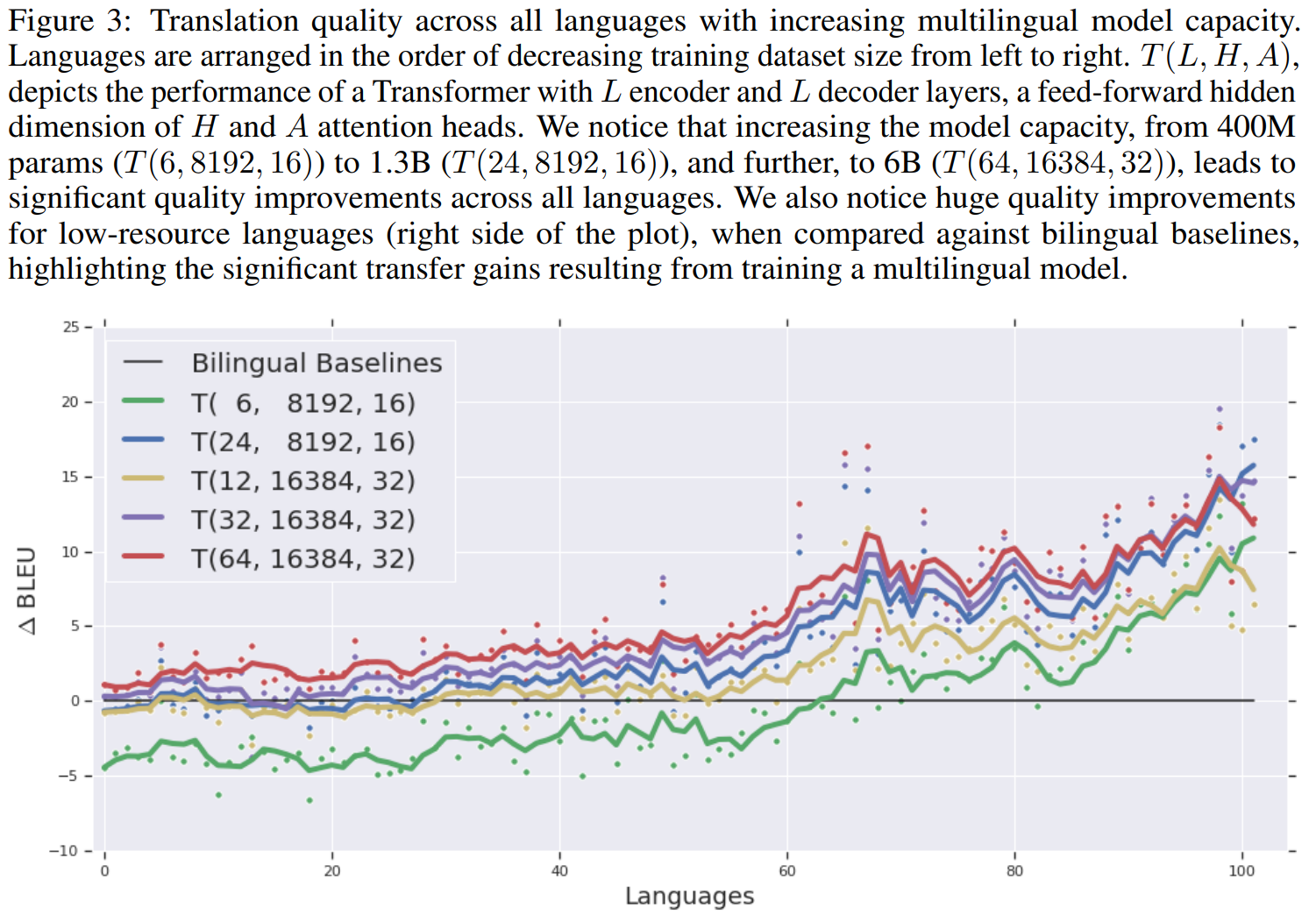
和的参数量相同但深度不同。这两个模型在资源多的情况下(图中左边)性能相似,在资源少的情况下(图中右边)更深的模型性能更好。对比,只有深度加深,但性能提升非常大。
但是更深的模型的训练难度更大:受噪声影响更大、梯度消失。使用了一些初始化调整和裁剪进行控制。
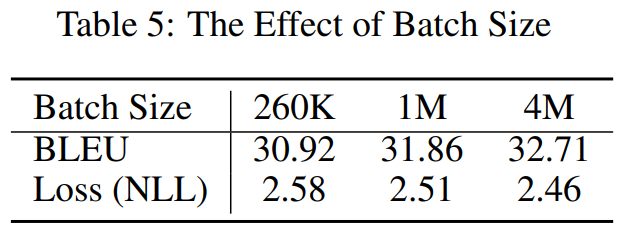
增大批次大小也能提升性能。
讨论
Mesh-Tensorflow使用了SPMD框架,通信成本开销很大,而且SPMD也限制了其应用场景,扩展性不好。
PipeDream为了减小通信开销,将前向传播的过程流水线化,并穿插反向的梯度计算。但它有权重老旧以及规模无法拓展的问题。
GPipe解决了如上问题,但它要求一个层只能在一个加速子上;除此之外,它引入了batch之间的计算开销。
